
2022. 08. 18. (목) 부터 시작한 수업
매일 매일 올리기로 마음 먹었으나 ...
너무 늦어버린 나머지 최근꺼부터 역순으로 올리기로 마음 먹었다..!
2022.09. 07 (수) ~ 08 (목) 벌써 3주나 지났네..
오늘부터 AI 수업이 시작된다.
09/07(수)
- AI 서비스 개발 실무
- 인공지능 개론
- Data의 활용과 Azure ML Studio (Azure Machine Learning Studio)
09/08(목)
- Regression 알고리즘/ Classification 알고리즘의 이해와 실습
수업에 앞서 ML(Machine Learning) 기계학습을 위한 환경 설정을 하였다.
머신러닝이란?
우리말로 하면 기계 학습으로 불리우는 머신러닝은
컴퓨터를 사람처럼 학습시키면 사람의 도움 없이도
컴퓨터가 스스로 새로운 규칙을 생성할 수 있게 할 수 있지 않을까?
하는 발상으로 시작되었다고 한다.
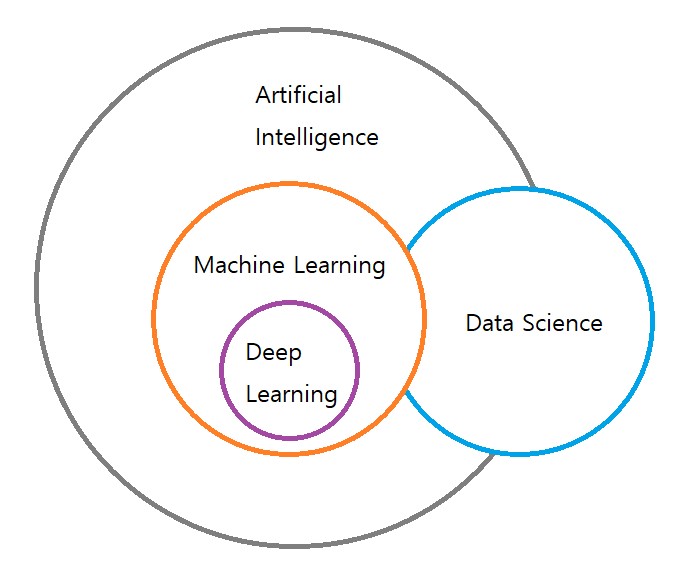
머신러닝은 인공지능의 한 분야로 컴퓨터가 학습할 수 있도록 하고 그런 알고리즘과 기술을 개발하는 분야를 말한다.
AI란? (Artificial Intelligence)
시각적 인식
텍스트 분석
음성
의사 결정
사람과 비슷한 네 가지(시각적 인식, 텍스트 분석, 음성, 의사 결정)의 능력을 보유한 소프트웨어다.
딥러닝(Deep Learning) 이란?
머신러닝이 사람의 학습을 모방하는 정도라면 딥러닝은 사람의 뇌 자체를 모방하려는 목적으로 시작되었다.
사람의 뇌 구조를 이루는 뉴런의 연결구조인 신경망을 모방해
인공신경망(ANN : Artificial Neural Network)을 만들게 되었고, 여러 층의 ANN을 이용하는 것이다.
대규모의 데이터에서 특징을 추출하여 중요한 패턴 및 규칙을 학습하고 이를 기반으로 예측이나 의사결정을 수행한다.

소프트웨어 엔지니어를 위한 AI
소프트웨어 개발 기술과 AI의 개념 파악이 필요하다. 그 내용에는 이런 것들이 있다.
소프트웨어 개발 기술에 필요한 것
- 코드 작성(C#, Python, Node.js 등)
- API 사용(REST 또는 SDK)
- DevOps(소스 제어, CI/CD)
AI의 개념 파악에 필요한 것
- 모델 학습 및 유추
- 가능성 및 신뢰도 점수
- 책임 있는 AI 및 AI에 적용되는 윤리 원칙
머신러닝이란?
- 수학적 알고리즘을 사용하여 예측 모델을 만드는 AI 기술
- AI의 하위 집합
- 머신 러닝 알고리즘은 명시적으로 프로그래밍하지 않고도 예측이나 결정을 내리기 위해
"훈련 데이터(training data)"로 알려진 샘플 데이터를 기반으로 수학적 모델을 생성 - 명시적으로 프로그래밍되지 않은 특정 작업을 수행하기 위해 인간처럼 생각하도록
기계를 가르치는 프로세스로 정의할 수 있다.
머신러닝 워크플로(작업 흐름) 5단계
1. 문제 정의
문제 해결을 시작하기 전에 먼저 문제가 정확히 무엇인지 확인해야 한다.
문제가 무엇인지, 기계 학습을 사용하여 문제를 해결할 수 있는지 여부 등을 파악해야 한다.
2. 데이터 수집
정의된 문제를 기반으로 데이터 수집, 데이터는 매우 중요하므로 주의해서 수집해야 한다.
분석에 필요한 모든 필수 factors에 해당하는 데이터가 있는지 확인해야 한다.
3. 데이터 정제(가공)
좋은 데이터를 되도록 데이터를 정제해야 한다.
예를 들면, 이상값을 제거하거나 누락된 정보를 처리하는 것 등이 포함된다.
4. 모델(model) 개발
문제를 해결하는데 사용할 기계 학습 모델(ML model)을 생성한다.
이 모델은 데이터를 입력으로 받아 계산을 수행한 다음 산출물(output)을 생성한다.
5. 모델(model) 평가
모델의 정확성을 확인하고 모델에 새 데이터에서 입력하면 작동하는지 모델 평가를 한다.
머신러닝의 장점
1. 경향(Trends) 및 패턴 식별
기계 학습(머신러닝)은 많은 양의 데이터를 검토하고 우리에게 분명하지 않은 특정 추세와 패턴을 파악할 수 있도록 한다.
예를 들어, Amazon(아마존)은 고객의 구매 패턴과 검색 동향을 분석하고 제품을 예측한다.
2. 지속적인 개선(향상)
기계 학습 알고리즘은 우리가 제공하는 데이터에서 학습할 수 있어 정확성과 효율성이 계속 향상된다.
이를 통해 더 나은 결정을 내릴 수 있다.
3. 자동화(Automation)
모든 단계에서 프로젝트에 대해 관리할 필요가 없다. 기계학습은 기계에 학습 능력을 부여하는 것을 의미하기 때문에
기계가 스스로 예측하고 알고리즘을 개선할 수 있다. 일반적인 예로 백신 소프트웨어로 그 새로운 위협을 인식할 때 필터링하는 방법을 학습한다.
머신러닝의 단점
데이터 획득(확보)
머신 러닝을 학습하려면 방대한 데이터 세트가 필요하다.
설문조사에서 데이터를 수집할 때 많은 양의 가짜 데이터와 잘못된 데이터가 포함될 수 있으며 가끔 데이터의 불균형을 발견하여 모델의 정확도가 떨어지는 상황에 직면한다.
높은 오류민감도(error-susceptibility)
기계 학습을 사용하여 프로세스를 자동화하기 쉽기 때문에 중간에 있는 데이터가 부적절할 때가 있다.
이로 인해 잘못된 결과나 오류가 발생할 수 있다.
예를 들어, 편향된 훈련 세트에서 오는 편향된 예측으로 끝날 경우 고객에게 관련 없는 광고가 표시될 수 있다.
시간(Times)과 자원(Resources)
기계 학습 모델은 엄청난 양의 데이터를 처리할 수 있음.
데이터의 양이 많을수록 데이터에서 학습하고 처리하는 시간도 늘어나며 이로 인해 추가 리소스가 필요할 수 있다.
파이썬 머신 러닝 라이브러리(Python Machine Learning Libraries)
Numpy(넘파이)
Numpy는 사용자에게 강력한 컴퓨팅 기능을 제공한다.
느린 수학적 계산 문제를 해결하고 사용자가 다차원 배열의 도움으로 방대한 계산을 수행할 수 있게 한다.
Pandas(판다x, 판다스)
Pandas는 사용자에게 대규모 데이터 세트를 처리할 수 있는 기능을 제공한다.
데이터 읽기 및 쓰기, 데이터 정리 및 변경 등을 위한 도구를 제공한다.
Scipy(싸이파이)
Scipy는 과학 및 기술 계산에 사용한다.
Numpy의 다차원 배열에서 동작한다.
Scikit-Learn(사이킷-런)
Scikit-learn은 Python(파이썬)의 대표적인 데이터 분석 라이브러리다.
지원 벡터 머신(support-vector machines), 랜덤 포레스트(random forests), 그래디언트 부스팅(gradient boosting),
k-means 및 DBSCAN을 포함한 다양한 분류(classification), 회귀(regression) 및 클러스터링(clustering) 등과 같은 알고리즘을 지원한다.
TensorFlow(텐서플로)
Tensorflow는 기계 학습을 위한 무료 오픈 소스 소프트웨어 라이브러리다.
다양한 작업에서 사용할 수 있지만 심층 신경망(deep neural networks)의 훈련 및 추론에 특히 중점을 두었다.
다음은 Anaconda(아나콘다)에 대한 내용을 작성할 예정이다.... Coming Soon ... 젭알..
참고문헌 및 자료&링크
- 원철연 강사님 MCT, MVP (Developer Technologies) 강의
- https://ikkison.tistory.com/49
'개발' 카테고리의 다른 글
| 내 GitHub 프로필 만들기 (README.md file Create) (0) | 2022.12.15 |
|---|